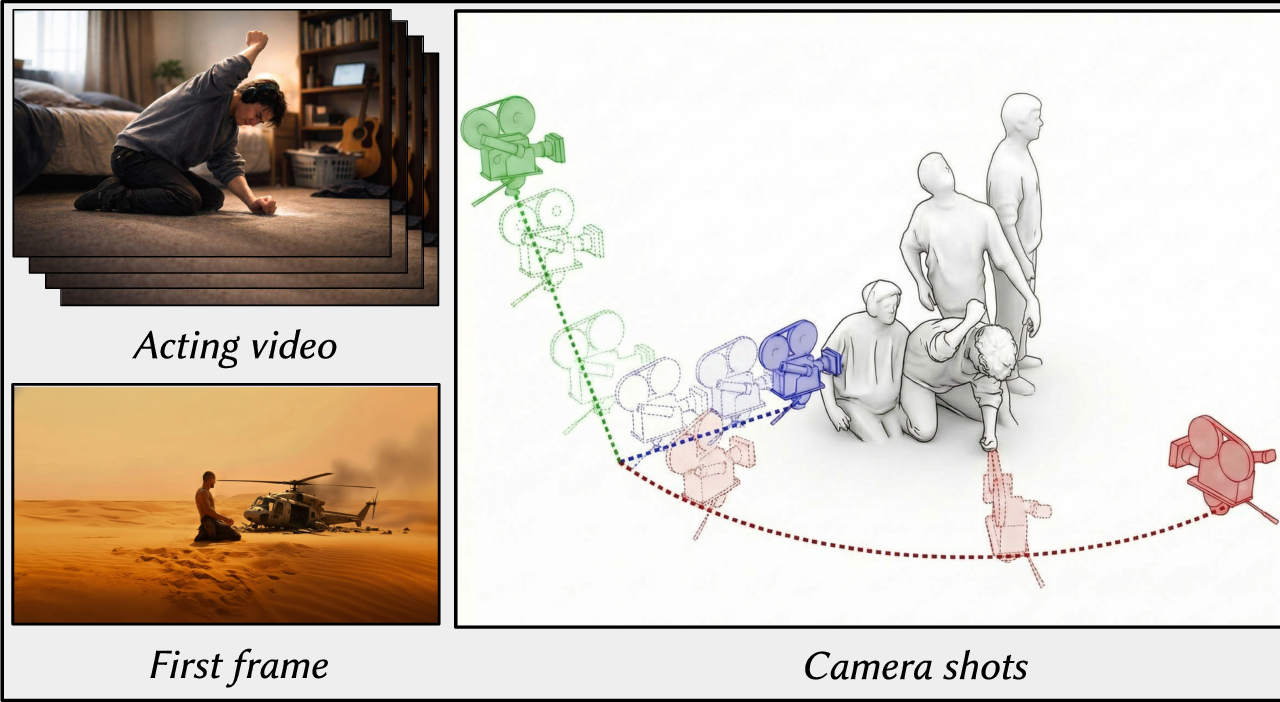
Zero-Shot Joint Camera and 3D Motion Control for Video Generation
For artistic applications, video generation requires fine-grained control over both performance and cinematography—i.e., the actor's motion and the camera trajectory. We present ActCam, a zero-shot method for video generation that jointly (i) transfers character motion from a driving video into a new scene and (ii) enables per-frame control of intrinsic and extrinsic camera parameters. ActCam builds on a pretrained image-to-video diffusion model that accepts conditioning in terms of scene depth and character pose. Given a source video with a moving character and a target camera motion, ActCam generates pose and depth conditions that remain geometrically consistent across frames. We then run a single sampling process with a two-phase conditioning schedule: early denoising steps condition on both pose and sparse depth to enforce scene structure, after which depth is dropped and pose-only guidance refines high-frequency details without over-constraining the generation. Compared to pose-only control and other pose+camera methods, ActCam improves camera adherence and motion fidelity, and is preferred in human evaluations—especially under large viewpoint changes.
Joint acting-motion and camera-trajectory control in image-conditioned video generation—enabling controllable cinematography without additional training, outperforming finetuned approaches.
A geometry-grounded conditioning pipeline aligning motion and scene geometry to the target camera, with reference-character removal and depth alignment preventing static/dynamic interference.
An inference pipeline adapting conditioning to the denoising step—depth enforces structure early, then pose-only guidance refines details—preserving dynamic scene elements.
ActCam is a pure inference-time method. No finetuning required—just carefully constructed conditioning signals fed to a pretrained backbone.
The reference character is inpainted out of the reference image, and a monocular depth estimator (MoGe) creates a background-only 3D mesh. This prevents static character geometry from conflicting with dynamic motion conditioning.
A monocular 3D human motion estimator (GVHMR) recovers an articulated motion sequence from the acting video, providing a stable 3D signal that avoids 2D keypoint ambiguities under viewpoint changes.
The recovered motion is aligned to the background 3D mesh via a weighted affine depth transformation, ensuring geometrically consistent placement respecting character-environment contacts.
Both pose and depth+pose control signals are rasterized under the target camera trajectory with depth-aware back-to-front ordering, handling self-occlusions correctly.
Early denoising steps use depth+pose to lock scene structure and camera motion. Later steps switch to pose-only, allowing high-frequency detail refinement without propagating depth artifacts.
Full geometric conditioning establishes 3D scene structure, camera viewpoint, and motion layout during high-noise early steps.
Depth is dropped. Pose-only guidance refines textures, lighting, and high-frequency details without over-constraining generation.
ActCam is evaluated on both static and moving camera benchmarks using VBench metrics, motion fidelity (MPJPE), and geometric consistency (Sampson Error), alongside a human preference study.
| Model | Average ↑ | SC ↑ | BC ↑ | AF ↑ | IQ ↑ | TC ↑ | MS ↑ | MPJPE ↓ | SE ↓ |
|---|---|---|---|---|---|---|---|---|---|
| Uni3C | 0.8370 | 0.9084 | 0.9380 | 0.5688 | 0.6640 | 0.9607 | 0.9821 | 0.2121 | 0.5665 |
| RealisDance DiT | 0.8351 | 0.9209 | 0.9342 | 0.5417 | 0.6448 | 0.9803 | 0.9888 | 0.2123 | 0.4528 |
| ActCam (Ours) | 0.8497 | 0.9212 | 0.9350 | 0.5767 | 0.7212 | 0.9571 | 0.9872 | 0.2087 | 0.4546 |
| Model | Average ↑ | SC ↑ | BC ↑ | AF ↑ | IQ ↑ | TC ↑ | MS ↑ |
|---|---|---|---|---|---|---|---|
| Moore-AnimateAnyone | 83.78 | 94.65 | 94.90 | 51.56 | 66.34 | 97.16 | 98.07 |
| HumanVid | 84.68 | 93.69 | 94.94 | 55.58 | 67.45 | 97.87 | 98.52 |
| MimicMotion | 82.27 | 92.21 | 93.60 | 52.09 | 59.67 | 97.46 | 98.61 |
| Animate-X | 82.93 | 93.39 | 95.11 | 51.72 | 60.91 | 97.79 | 98.68 |
| Hyper-Motion | 84.04 | 93.58 | 94.97 | 52.97 | 65.52 | 98.19 | 99.01 |
| UniAnimate-DiT | 84.29 | 94.56 | 95.44 | 52.18 | 65.52 | 98.78 | 99.24 |
| VACE | 85.33 | 93.56 | 95.03 | 57.81 | 70.61 | 96.74 | 98.25 |
| Wan-Animate | 84.38 | 93.06 | 94.52 | 54.47 | 66.87 | 98.42 | 98.96 |
| SteadyDancer | 85.15 | 93.48 | 95.18 | 56.80 | 68.45 | 97.99 | 99.02 |
| ActCam (Ours) | 86.47 | 95.28 | 95.83 | 58.66 | 70.83 | 98.88 | 99.34 |
2AFC study with 17 users comparing ActCam vs. Uni3C on identical inputs. ActCam is considerably preferred across all criteria.
Each video visualizes the full ActCam conditioning pipeline. The top row shows the four input signals; the bottom shows the generated output.
Each pair shows the acting input (left) and ActCam's generated output (right), synchronized frame-by-frame. The camera motion preset is highlighted for each result.
If you find this work useful, please cite:
@inproceedings{elkhalifi2026actcam,
title = {ActCam: Zero-Shot Joint Camera and 3D Motion
Control for Video Generation},
author = {Omar El Khalifi and Thomas Rossi and
Oscar Fossey and Thibault Fouque and
Ulysse Mizrahi and Philip Torr and
Ivan Laptev and Fabio Pizzati and
Baptiste Bellot-Gurlet},
year = {2026}
}